
Outperforming Deep Reinforcement Learning with Luffy AI
Executive Summary
In the domains of robotics and industrial process control, few emerging technologies have garnered as much interest and industry excitement as deep reinforcement learning (Deep RL). Underpinned by the same deep neural networks powering the current generation of highly successful AI technologies, Deep RL leads the field on many control challenge benchmarks. However, despite highly publicised results in games1 and simulated physical challenges2 , these controllers are too often confounded by the complexities of the real world, barring them from the industrial plant, the refinery, and the factory floor. Recognised barriers to adoption include the difficulty of training Deep RL controllers, the computational (in)efficiency of such controllers once trained, and the inability of trained controllers to “cross the reality gap”. By challenging the field’s core assumptions, casting off the deep learning paradigm, and developing its own next-generation AI technology, Luffy has surmounted all three, making Luffy’s the most credible AI technology in the space. Further, in this short note, we demonstrate that Luffy’s AI is competitive with state of-the-art Deep RL algorithms on its own turf. With its superior performance, ability to adapt to its environment, and unparalleled capability per Watt, Luffy’s AI makes industrial AI control a reality
The Promise of AI Control
Control systems pervade modern industry. Today’s factories employ a plethora of controllers, automating the function of heating elements, air-compressors, conveyor belts, robotic arms, and more. Slow-evolving and high-value applications may be driven by Model Predictive Control (MPC), in which a high-fidelity model of the system is executed live to perform optimal control actions. Many more are controlled by PID, a simplistic linear controller which is tuned to particular operating conditions. These approaches have complementary limitations. MPC performs very well, but the computational cost, degree of expertise, and need for a good physical model discount its use for most problems. PID, on the other hand, is computationally simple and relatively easy to configure, but performs poorly at the edges of its tuned behaviour, needs frequent retuning, and still requires expertise to achieve nominal performance in more complex systems. Other Advanced Process Control (APC) techniques require "PhD’s-in-the-loop" to even be considered. With ease of configuration making PID the most common choice, factories are left with poorly approximated controllers whose tuning region fails to cover the full operational envelope of the hardware. The consequences of this are dire: reduced yields, increased tool attrition, increased waste, increased energy usage. Intolerance to machine imperfections incurs more frequent maintenance and re-tunings by control engineers.
“Automated” processes require constant human supervision, intervention and manual tuning on the fly. AI control is needed. A smarter controller would be able to learn the full dynamics of the system, coping with edge cases and improving efficiency at every stage of the process. Adaptive AI can adjust to degraded machinery, variations in load or material, and other extraordinary operating conditions; beyond merely improving what automation already exists, AI can take on new challenges, automating more than ever before, and enabling new processes which are as yet infeasible due to limitations of control.
1 E.g. the traditional game of Go (AlphaZero) or the popular eSport game StarCraft II (AlphaStar) 2 Such as the wide array of control problems in the OpenAI Gym and Deepmind Control suites
The Challenges of the Real World
Despite the clear value of AI control, actual uptake is thin on the ground. Deep RL, the dominant AI technology, has made some inroads, but the too-frequent experience in industry is: “Deep RL Doesn’t Work Yet” [1]. This is largely due to the motivations driving current practitioners. The baselines and benchmarks used to evaluate deep RL algorithms have been developed by academics, not end-users, and are more often idealised toy problems than anything resembling a real world control system.

Many Deep RL breakthroughs were developed on nonphysical benchmarks like the Atari57 challenge [2].
Unlike games and idealised simulations, real world control systems are characterised by imperfections, statistical variations, and sometimes severe delays between sensing, action, and response. A viable AI controller must be able to see through noisy, late and misleading sensor data; learn and account for system dynamics and un-sensed system parameters, such as the degree of thermal coupling between two tanks, or the chemical interactions between materials; and adapt to changes in the environment, such as ambient temperature or hardware degradation. And all of this must execute “in real time”, at least as fast as the underlying dynamics require.
Deep RL controllers (also called ‘agents’) often train well in simulation, only to fail at the point of “sim2real transfer”. Such agents are unable to “cross the reality gap” – to account for parameter and phenomenological differences between the simulation and those experienced in situ. Even when sim2real transfer succeeds, the resulting agents often exhibit unpredictable behaviours when exposed to situations slightly outside their training domain; what’s more, the compute requirements of such agents usually exceed the available hardware for a given plant.
A Question of Mathematics
In these cases, the intrinsic properties of deep networks work against them. This can be seen from a simple mathematical argument: even small deep networks have hundreds of thousands of free parameters to tune – each parameter is a ‘dimension’. As architectures are fixed, this is necessarily a greater number than the true dimensionality of the problem. As with fitting a polynomial to points on a curve, the more parameters you have, the more the fit diverges both outside and between the points (extrapolation and interpolation, respectively). This is why deep networks perform badly at the edges of their trained behaviour – they are over-parameterised.
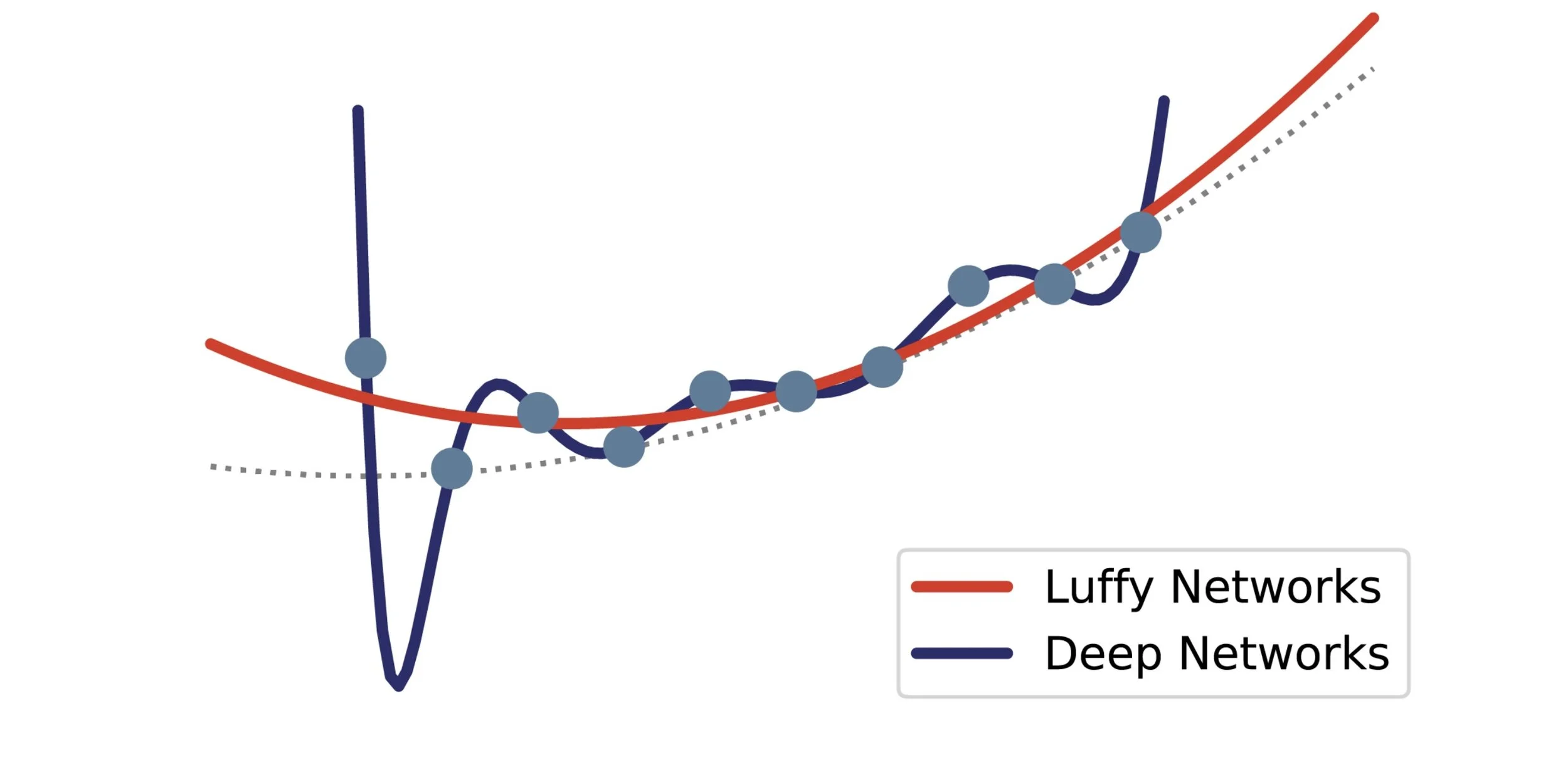
Overfitting due to over-parameterisation
As the shortcomings of Deep RL have been more widely publicised [1], [10], researchers have increasingly focussed on the barriers to its adoption. Amongst others, a recent paper from Google Research [11] identified the major control challenges for reinforcement learning in the real world. In order to compare the capabilities of different algorithms in real world settings, they propose the Real World Reinforcement Learning Suite (RWRL), adapting four simulated challenges from the Deepmind Control suite [12]. They also present the performance on RWRL of two state-of-the-art Deep RL algorithms: DMPO and D4PG.
Network ‘regularisation’ is an imperfect solution to this. Regularisation encourages network parameters to be small, forcing many parameters toward 0. This leads to “dead structure” accounting for as much as 90% of the network, burning compute power for no benefit [3]. This has led to what researchers have termed the “lottery ticket hypothesis”: because deep learning uses a local optimiser (gradient descent), the initial network architecture must be large enough to contain at least one “winning ticket”, a sparse sub-network whose initial weights converge to a good local solution. In this sense, trained deep networks carry the weight of their search-space with them.
These weaknesses are reflected in the success stories. A recent academic survey of sim2real transfer found that most applications of Deep RL were either high-level control tasks such as navigation, path-finding, and determining setpoints, rather than low-level control such as setpoint-following; where controllers did perform low-level control, the hardware was either toy-like or heavily engineered to behave more like ideal systems, with soft deadlines. [4].
Optimal Architectures
By contrast, and against the grain of current AI approaches, Luffy’s neural networks are not deep, and do not use a local optimiser like gradient descent. Instead, Luffy has developed its own AI technology based on neuroevolution [5].
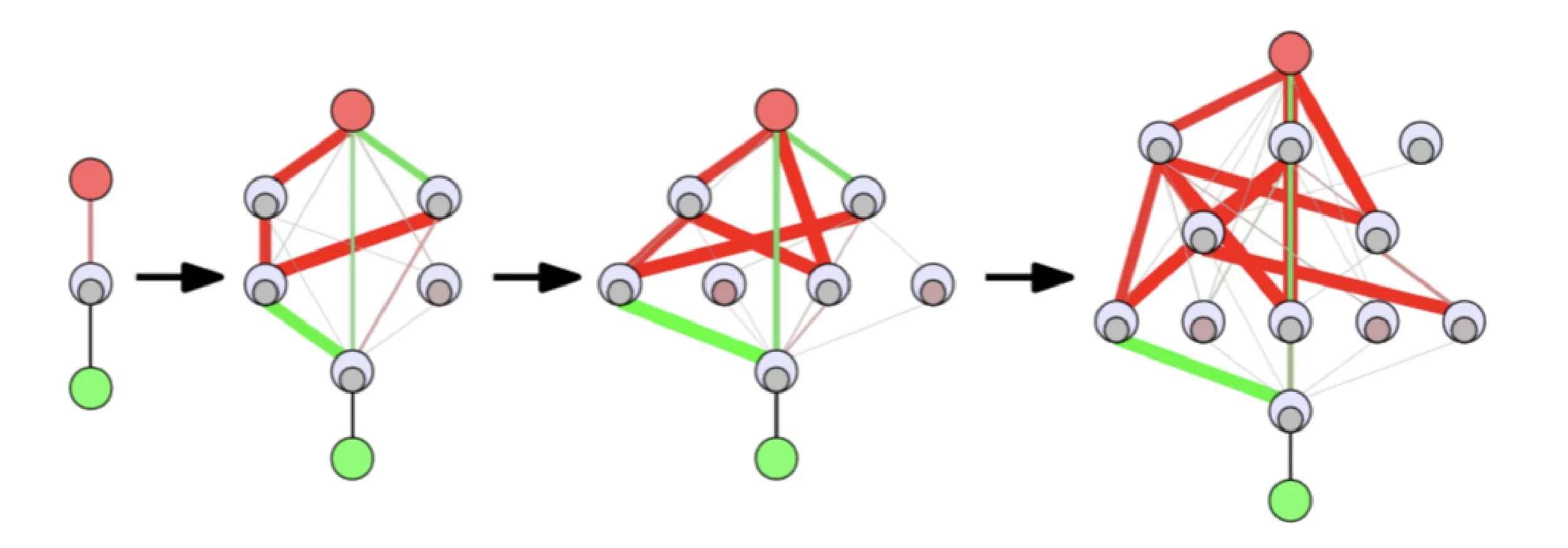
Neuroevolution evolves network structure alongside parameters
Neuroevolution evolves network structure as well as weights, meaning that the resulting networks are no larger than necessary to solve the specified problem. The use of a genetic algorithm helps avoid local optima, and isolates different search directions rather than storing them all in one network as “lottery tickets”. Additionally, there are fewer constraints on the resulting architecture, allowing Luffy’s networks to leverage biologically inspired mechanisms such as neuroplasticity and neuromodulation3. This in turn increases the functional density of neurons and synapses, doing more with less. We call the resulting networks Adaptive AI. Adaptive AI is the missing ingredient for making reinforcement learning work in the real world4. Adaptive AI can modify its state as it executes, adjusting to unexpected responses to its actions. This of course allows it to adjust to evolving system state such as degraded machinery or environmental obstructions; but also to seamlessly cross the reality gap, often on the first attempt, by adjusting to the differences between its simulation and the real world. It is these advantages which have led Gartner to identify Adaptive AI as a Top 10 Strategic Technology Trend for 2023 [7]–[9].
Beating Deep RL in the real world

Identified Challenges
As the shortcomings of Deep RL have been more widely publicised [1], [10], researchers have increasingly focussed on the barriers to its adoption. Amongst others, a recent paper from Google Research [11] identified the major control challenges for reinforcement learning in the real world. In order to compare the capabilities of different algorithms in real world settings, they propose the Real World Reinforcement Learning Suite (RWRL), adapting four simulated challenges from the Deepmind Control suite [12]. They also present the performance on RWRL of two state-of-the-art Deep RL algorithms: DMPO and D4PG.
The RWRL suite implements several confounding factors atop the baseline (i.e. idealised) task:
- Delays on actions, observations, and rewards
- Repeated actions (equivalent to reduced control frequency)
- Gaussian noise on actions and observations
- “Stuck” and “dropped” observations (set to previous value or 0)
- Variation in body parameters between episodes.
- Gaussian dummy inputs
3 Amongst other benefits, neuromodulation underpins attention mechanisms in real biological brains [6].
Attention mechanisms form a foundational basis for recent advances in deep learning, such as large language models (LLMs), but
implementations without neuromodulation remain extremely power-hungry compared to, forexample, the human brain.
To compare our technology to Deep RL, we took the Cart-pole “Swing Up” task, and trained networks for the baseline and each of the three “combined“ challenges, which include incrementally harder combinations of all of the above. The “easy” challenge is quite representative of many control systems; by the “hard” challenge, the system is nigh-on uncontrollable.
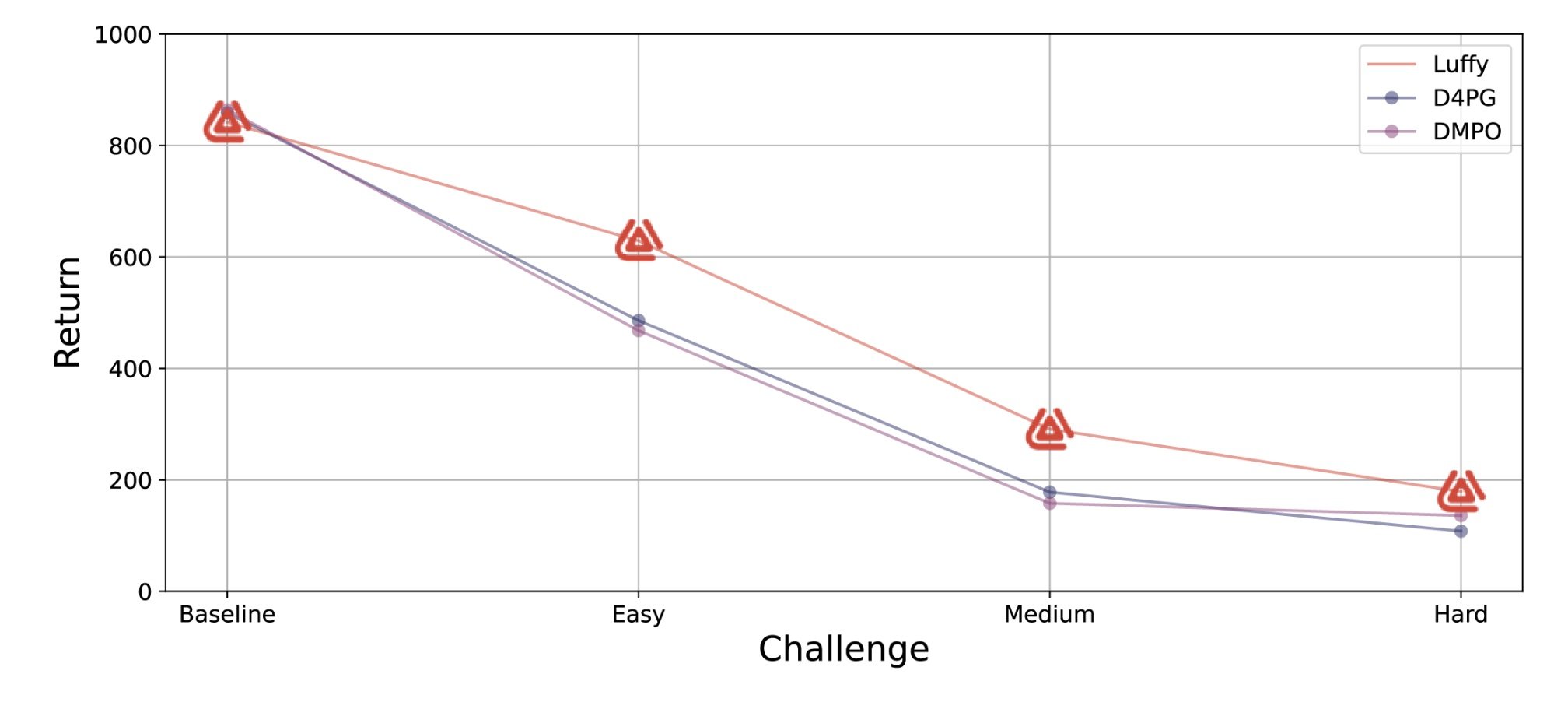
Luffy outperforms the competition in realistic settings. Data reproduced from [13].
As can be seen from the graph above, Luffy’s AI garners about equivalent reward in validation for the idealised baseline challenge (840 vs ∼ 860). However, for each of the “realistic” challenges, Luffy outperforms the competition. This can be seen as a direct comparison of Luffy’s non-local optimiser and network architecture vs Deep RL. For a fair comparison to the published results, we omitted many steps which we would perform as standard process for a real application; had they been incorporated, our performance could only improve:
- We did not seed the optimiser with an a priori strategy based on our domain knowledge.
- We did not expand or modify the domain sampling.
- We did not perform any additional reward shaping.
- We did not employ curriculum learning, decomposing the problem to guide the search
While the quality of solutions found by neuroevolution is often superior to those found by deep learning, the training time is significantly more. In this case, training took approximately 3 hours compared to 1 hour to train DMPO in a replication experiment. However, what is remarkable is the relative sample efficiency of Luffy’s agents compared to Deep RL. For example, to train on the baseline problem, Luffy’s training system used only 10 unique samples for training to achieve its score on a validation set of 100 unseen episodes. By comparison, DMPO and D4PG were trained on approximately 2000 unique episodes before convergence. For this comparison to be completely fair, of course, we need to retrain DMPO and D4PG on only 10 unique episodes for as many epochs as necessary for convergence and then compare the performance; however, with sample efficiency a recognised 6 issue in the literature, this result indicates the quality of our AI’s generalisation capabilities.
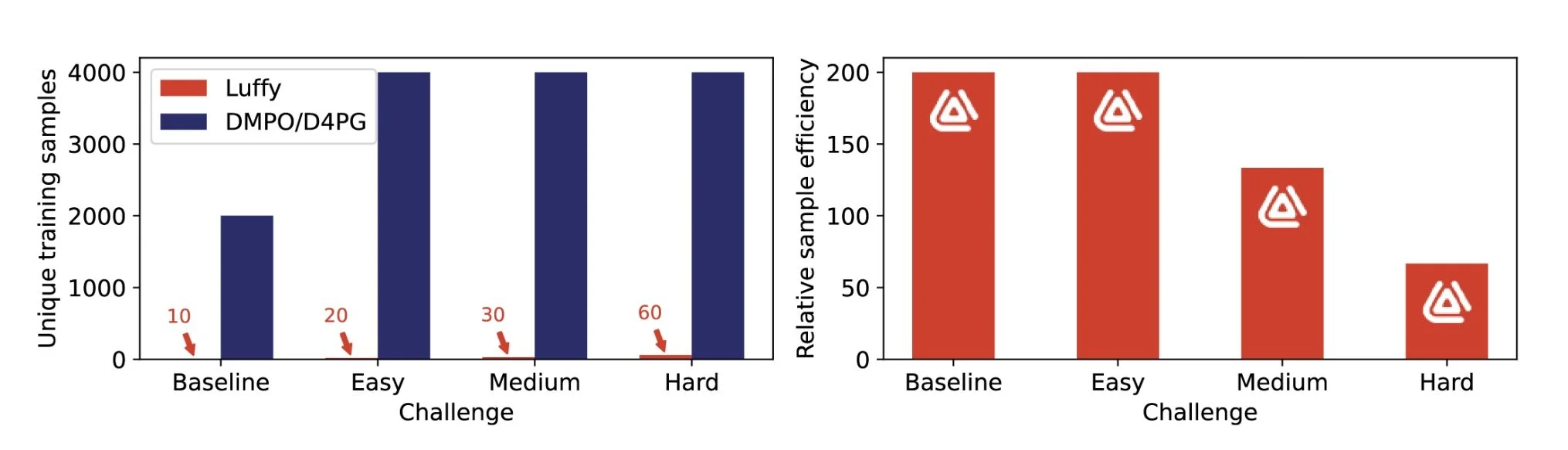
Luffy’s controllers take fewer unique samples to train than Deep RL, equating to higher sample efficiency.
4 This is much like how baby deer are able to walk shortly after being born due to pre-encoded neural structure.
Temporary (i.e. neuromodulated) neuroplasticity allows them to adapt their generalised walking capability to the specific body they are born
with, a phenomenon referred to in the neuroscience literature as precociality.
Unparalleled capability per Watt
Achieving superior performance to Deep RL is one thing - but the benefits of neuroevolution are best seen in how efficiently the discovered controller is encoded. The competing Deep RL agents each have a minimum of 132608 parameters5; the best Luffy network has 334 and the worst has 728, a saving of more than 100×.
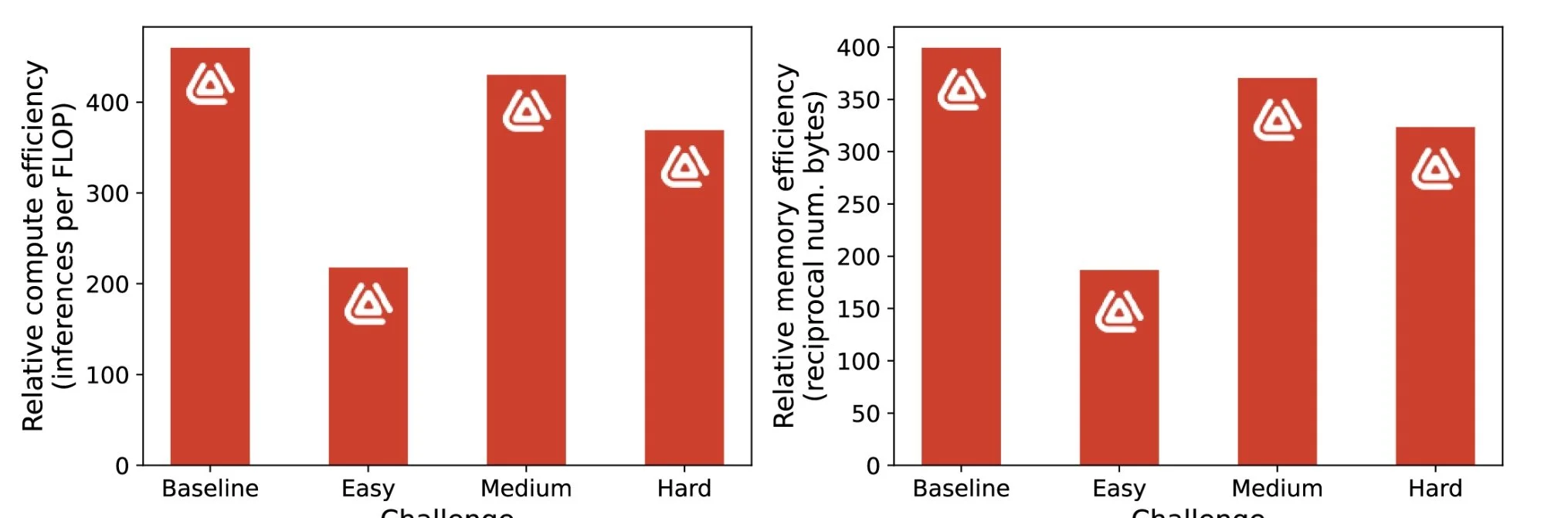
Luffy’s networks are 100s of times more compute and memeory efficient than Deep RL.
Luffy controllers have 300-400× fewer parameters than the equivalent Deep RL agent (directly proportional to bytes required to store the network), and about equivalent increases in compute efficiency (roughly measured in FLoating point OPerations, or FLOP). The network trained for the Easy challenge is about twice as big as the others due to random chance – the best-performing network on validation happened to evolve more structure than the others. However, were compute or memory footprint key concerns, network size could be constrained in the optimiser.
The efficiency of the encoding translates directly into either faster execution, or reduced compute resources needed to run the controller. This efficiency is the key to unlocking the potential of AI in industry and robotics. The adoption pathway for industry will always be smoother if it is able to use low-cost, low-power companion computers, or better yet, existing compute resources. As can be seen from a recent survey [14], to run at 60 Hz, deep RL agents typically require at best the full compute capability of a modern single-board computer (SBC) such as Raspberry Pi 4 – at worst, they may be so intensive to need off premises compute. Moving mission-critical control systems into the cloud is not a winning proposition for most factories, incompatible as it is with typical fault-tolerance, cybersecurity and operational policies. Luffy’s AI allows critical strategic industries to keep control within the bounds of their physical security.
5 Necessary for a fully-connected architecture of size [5, 256, 256, 256, 1]
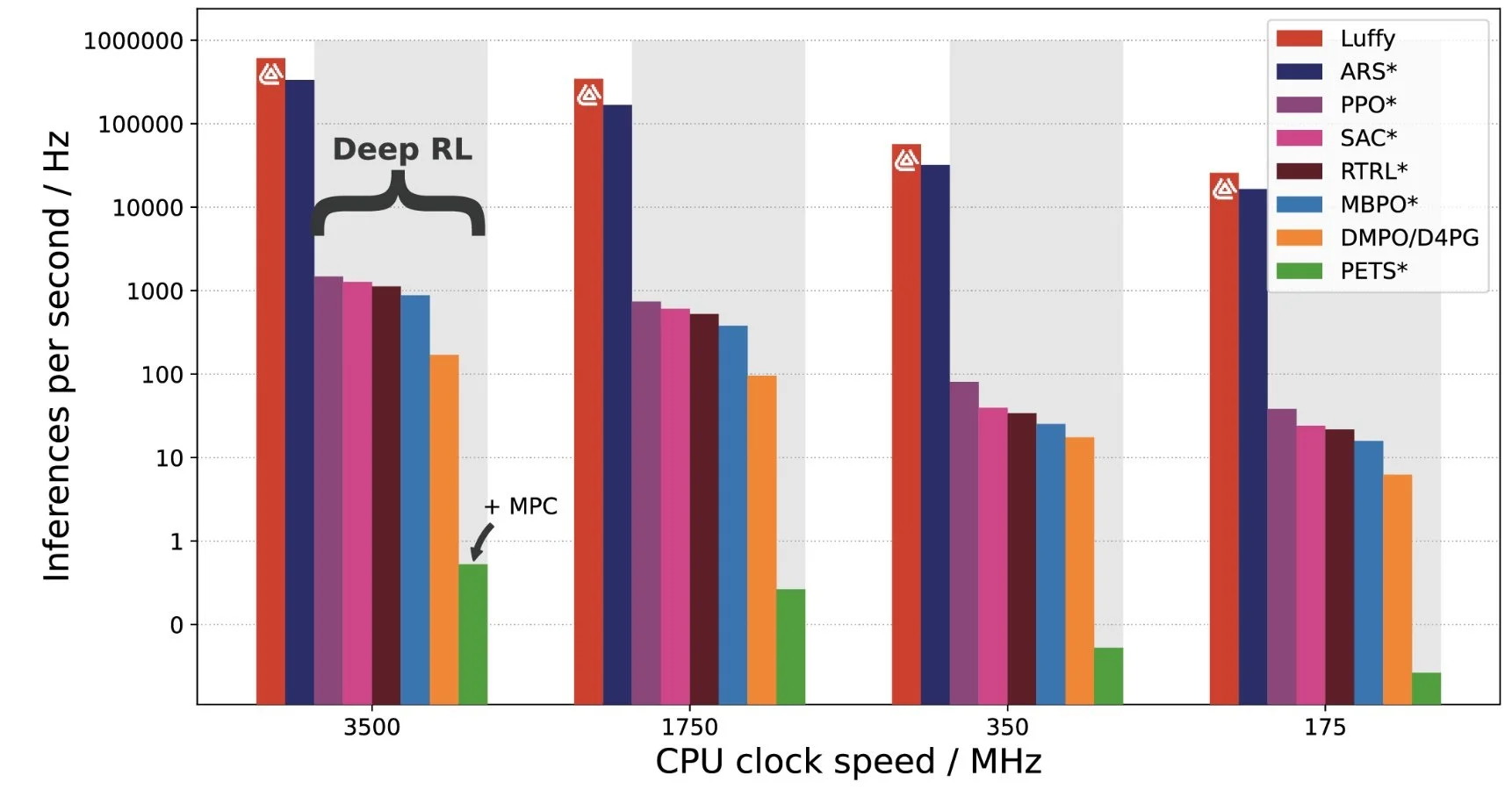
Luffy’s controllers execute faster than any competing AI solution. *indicates results reproduced from [14].
From the graph above, we see that Luffy’s AI comes out on top – an incredible 100-1000× faster on a single CPU than Deep RL solutions. In practice, this translates into a network which executes at 100 Hz with less than 1% of a single core of the four-core Raspberry Pi 4, leaving the rest for higher level tasks or controlling multiple plants at once. The only real competitor for execution speed is ARS, a linear controller with worse general performance compared to the other algorithms [14].
The benefits of Luffy appear even more stark when you compute the “capability per Watt” 8 or “capability per FLOP” – a measure of power expended to achieve a particular level of performance. We believe this best demonstrates the value proposition of our AI for computing at the edge.
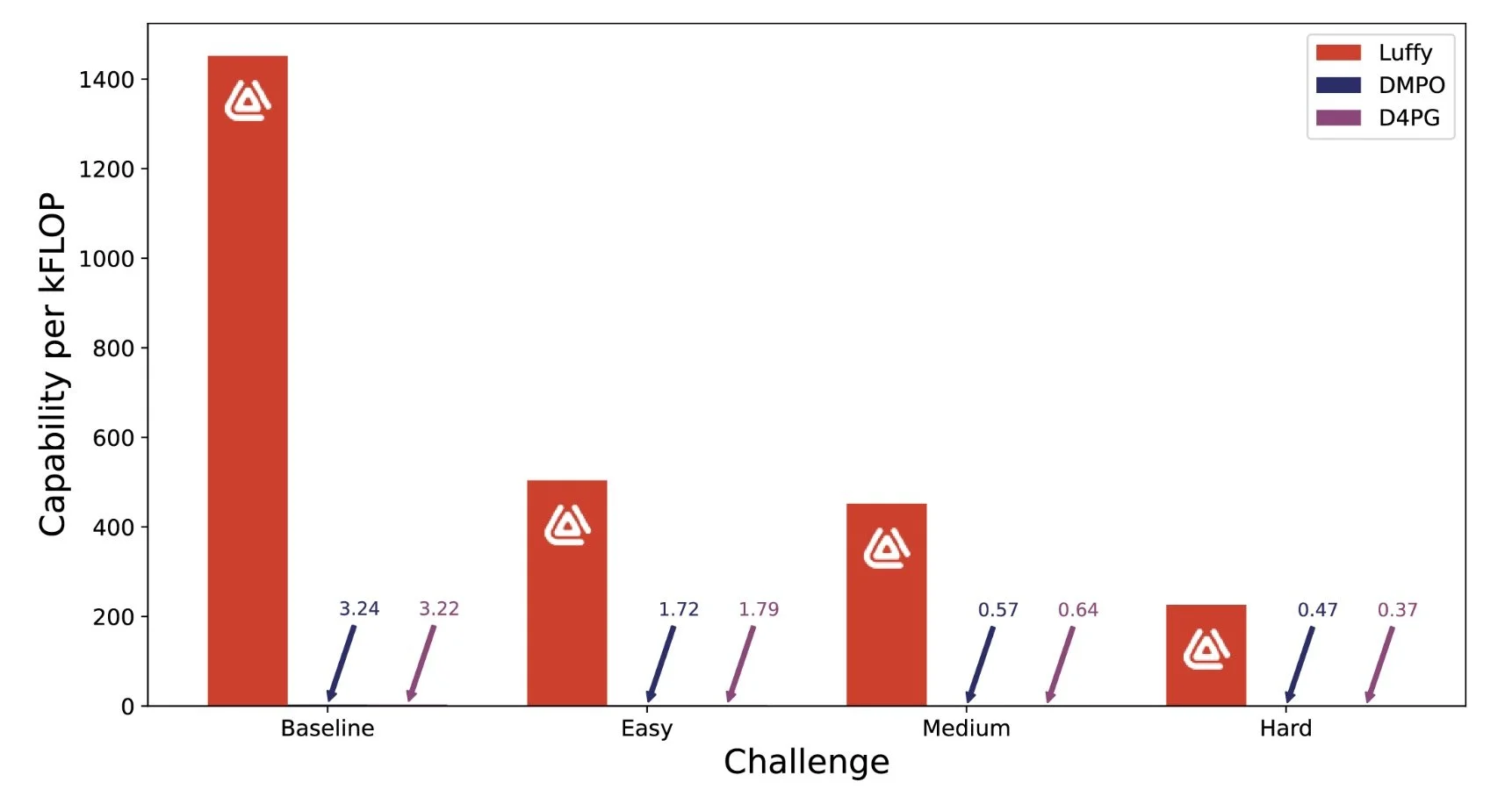
Luffy AI’s controllers execute faster than any competing AI solution. *indicates results reproduced from [14].
All of the above is only what we can achieve right now on a conventional general purpose PC or SBC. Luffy’s networks have a small enough memory footprint to be embedded into programmable integrated circuits (PICs) and microcontrollers, unlocking another level of compute and power efficiency – the infrastructure for this has already been developed. Most enticingly, however, Luffy’s networks were designed from the outset to work in both digital and analogue application specific integrated circuits (ASIC). Analogue ASIC promises the ultimate offering in efficient AI at milliwatt scale.

Drone flying autonomously using a Luffy AI controller.
References
[1] Alex Irpan. Deep Reinforcement Learning Doesn’t Work Yet. https://www.alexirpan.com/2018/02/14/rl-
hard.html. 2018.
[2] Greg Brockman, Vicki Cheung, Ludwig Pettersson, et al. OpenAI Gym. 2016. eprint: arXiv:1606.01540.
[3] Jonathan Frankle and Michael Carbin. “The lottery ticket hypothesis: Finding sparse, trainable neural
networks”. In: 7th International Conference on Learning Representations, ICLR 2019 (2019), pp. 1–42. arXiv:
1803.03635.
[4] Wenshuai Zhao, Jorge Peña Queralta, and Tomi Westerlund. “Sim-to-Real Transfer in Deep Reinforce-
ment Learning for Robotics: a Survey”. In: 2020 IEEE Symposium Series on Computational Intelligence
(SSCI). Dec. 1, 2020, pp. 737–744. DOI: 10.1109/SSCI47803.2020.9308468.. arXiv: 2009.13303[cs].
URL: http://arxiv.org/abs/2009.13303.
[5] Kenneth O. Stanley, Jeff Clune, Joel Lehman, et al. “Designing neural networks through neuroevo-
lution”. In: Nature Machine Intelligence 1.1 (2019). Publisher: Springer US, pp. 24–35. DOI: 10 . 1038 /
s42256-018-0006-z. URL: http://dx.doi.org/10.1038/s42256-018-0006-z.
[6] Alexander Thiele and Mark A. Bellgrove. “Neuromodulation of Attention”. In: Neuron 97.4 (Feb. 2018),
pp. 769–785. DOI: 10 . 1016 / j . neuron . 2018 . 01 . 008. URL: https://linkinghub.elsevier.com/re-
trieve/pii/S0896627318300114 (visited on 10/13/2023).
[7] Gartner. Gartner Top 10 Strategic Technology Trends for 2023. Blog post. Oct. 17, 2022. URL:
https://www.gartner.co.uk/en/articles/gartner-top-10-strategic-technology-trends-for-2023
[8] Gartner. Why Adaptive AI Should Matter to Your Business. Blog post. Oct. 27, 2022. URL: https://www.gart-
ner.com/en/articles/why-adaptive-ai-should-matter-to-your-business.
[9] Gartner. Gartner’s Top 10 Tech Trends for 2023. Presentation. Nov. 7, 2022. URL:
https://vimeo.com/864362449/844b31f538?share=copy.
[10] Julian Ibarz, Jie Tan, Chelsea Finn, et al. “How to Train Your Robot with Deep Reinforcement Learning;
Lessons We’ve Learned”. In: The International Journal of Robotics Research 40.4 (Apr. 2021), pp. 698–721.
DOI: 10.1177/0278364920987859. arXiv: 2102.02915[cs]. URL: http://arxiv.org/abs/2102.02915
[11] Gabriel Dulac-Arnold, Nir Levine, Daniel J. Mankowitz, et al. “Challenges of real-world reinforcement
learning: definitions, benchmarks and analysis”. In: Machine Learning 110.9 (Sept. 1, 2021), pp. 2419–
2468. DOI: 10.1007/s10994-021-05961-4. URL: https://doi.org/10.1007/s10994-021-05961-4.
[12] Yuval Tassa, Saran Tunyasuvunakool, Alistair Muldal, et al. “dm_control: Software and Tasks for Con-
tinuous Control”. In: Software Impacts 6 (Nov. 2020), p. 100022. DOI: 10.1016/j.simpa.2020.100022.
arXiv: 2006.12983[cs]. URL: http://arxiv.org/abs/2006.12983.
[13] Gabriel Dulac-Arnold, Nir Levine, Daniel J. Mankowitz, et al. An empirical investigation of the challenges
of real-world reinforcement learning. Mar. 4, 2020. arXiv: 2003.11881[cs]. URL: http://arxiv.org/abs/2003.11881
[14] Pierre Thodoroff, Wenyu Li, and Neil D Lawrence. “Benchmarking Real-Time Reinforcement Learn-
ing”. In: Proceedings of Machine Learning Research 181 (2022), pp. 26–41.